
はじめに
初めまして。データサイエンティストの山本です。レアジョブのデータを分析するお仕事をしています。私たちのチームは、「日本人1,000万人を英語が話せるようにする。」というサービスミッションを達成するために、我々の持つ英語学習者のデータから今まで気づいていなかった気づきや課題を発見し、さらに改善するための施策を考えています。
英語が話せるようになるって結局どういうことですか?
さて、この質問は私が一番最初に、チームリーダーに質問した実際の質問です。
皆さんなら、この問題をどのように解釈し、どのように捉え、どのように考えていきますか?
この問題は、抽象的で、複雑で、掴みどころのないのかもしれません。如何にして、科学的に検証可能な形で問題を解釈し、事象を捉え、理論的な背景を踏まえた状態で問題を思考していくかがポイントとなります。
私たちは、複雑な事象を細かく切り取って、小さな問題から認識し、それぞれの問題の関連性を解釈しながら、不確実で不合理な現実で、なるべく確率の高いアプローチを探求しています。
そして過去多くの研究がなされてきたこの分野の先人たちの恩恵を受けながら、最新の技術をブレンドして教育の科学を発展させていくことを私たちは目指しています。最新の技術を用いることで、従来の分析では見つけられなかった事象を発見できる可能性は高く、大量なデータを用いたより繊細なユーザー特性に合わせた分析を行うことの意義は計り知れません。
その中でも今回は比較的簡単で解釈のしやすい手法を用いたため、詳細については検証の余地が残されていることを明言しておきます。
それでは前置きが長くなりましたが、本題へ参りましょう。
日本人の英語の発話にはどういった特徴があるのだろうか
近年、日本では東南アジアを中心とした外国人労働者が増えてきています。厚生労働省の調べ1によると、昨年は日本で働く外国人労働者が過去最高を記録したとのことです。
深夜のコンビニエンスストア、宅配、ファミリーレストランなど様々なところで、彼ら/彼女らに接する機会があります。往々にして、彼らは日本語での会話を問題なくこなし、さらには突然の対応やお客さんとの他愛もない会話まで対処しています。いうまでもなく彼らは、日本語を話せると言っていいでしょう。
しかしそんな彼らの話し方はそれぞれ違っていて、文法や会話の内容には全く問題はないはずなのに、ある人は「日本語がうまい」ある人は「つたない」と感じてしまう時があります。
反対に、日本人も同じように英語で会話する時にはそのような事が起こっているかもしれません。
そしてそれが影響して、「日本人は英語があんまりうまくないのでは」と思われてしまうのは非常に勿体無いと思う次第です。
もしそうであれば、「それが何かを明らかにして少しでも違和感のないコミュニケーションを目指したい」というのが今回の課題設定です。
そこで今回は弊社が持つ学習者の発話データを元に「語句」という観点で見ていきたいと思います。
弊社ではレッスンの提供にWebRTC2を使用しており、外部サービスを利用したレッスン提供では難しかった発話音声を用いた解析を行うことができるようになりました。
当然ですがデータは匿名化され厳重に保管されています。
WordCloudを使う
※画像はEdvation x Summit 2018で弊社中村が使用したものを本記事用に加工
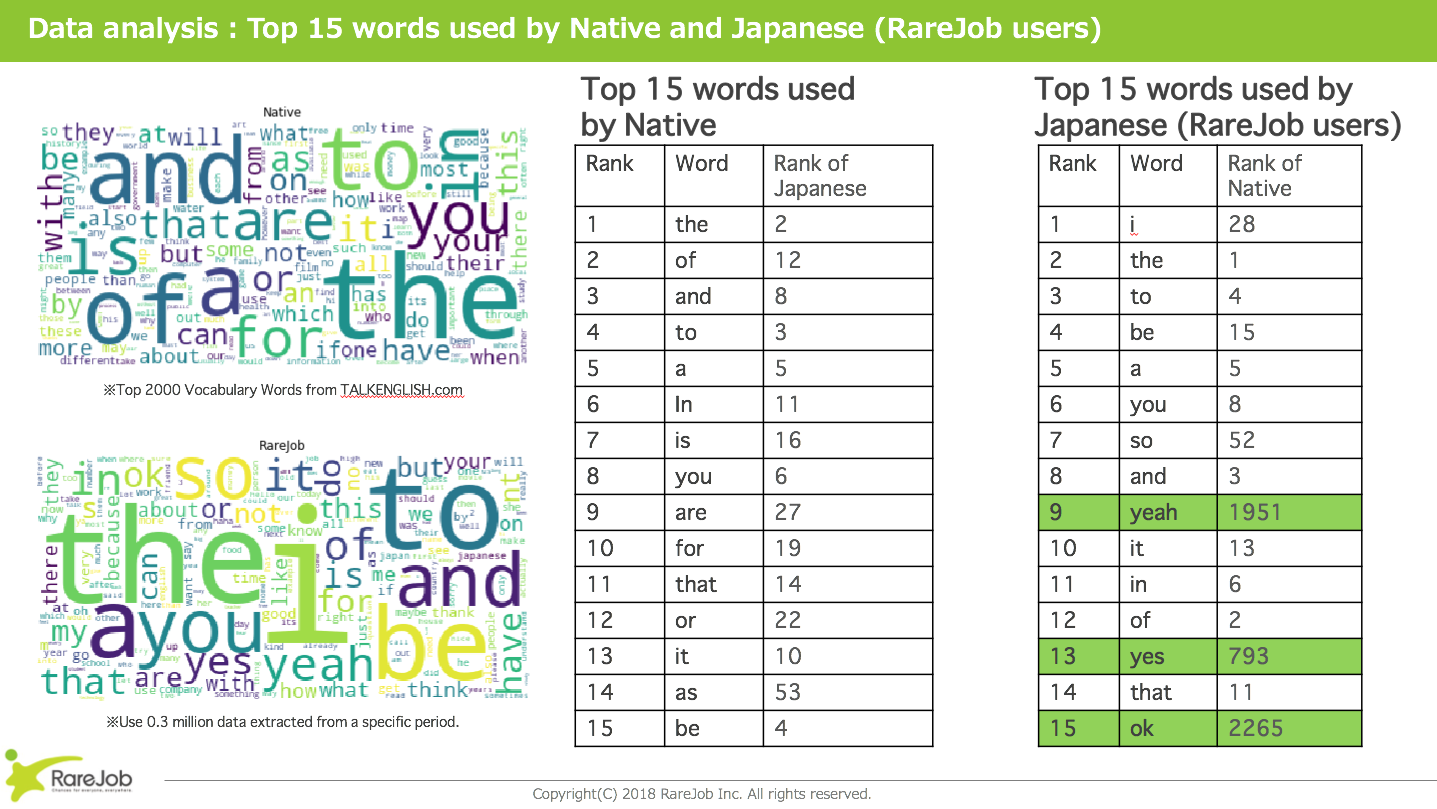
まずは最もシンプルな形で単語ごとの出現回数を算出し、上位のランキングとWordCloud3を用いて描画しました。
また、日本人のデータだけを利用すると特徴か判断できないため、ネイティブ4の利用頻度と比較もしています。
すると、以下のような点が見えてきました。
・Youはネイティブ、日本人共に使うが、Iは日本人の方が多く使う
・soは利用頻度が高いが、asは利用頻度が低い
・yeah, yes, okなどの言葉がネイティブに比べ極端に多い
特に3つ目のyeah, yes, okの多さは、他の二つに比べてかなりの差が出ています。
さらにここから単語の共起性を観察していきます。
N-gramを使う
N-gramを用いて単語の共起性を観察していきます。
使用するデータは弊社側のデータで、上位15位出現頻度を可視化します。
N-gram5とは、大まかに言えば文章に含まれる単語をn個ずつまとめる手法です。
例えば、” I am an English speaker.”をn=2で表現すると、(I, am), (am, an), (an, English), (English, speaker)となります。
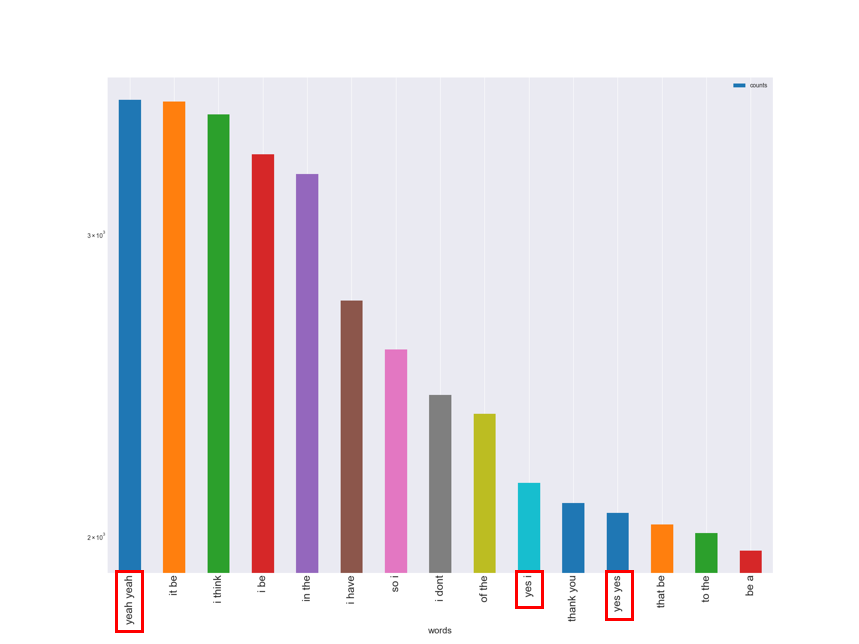
N=2 (x: words, y: count log-scaled)
N=3 (x: words, y: count log-scaled)
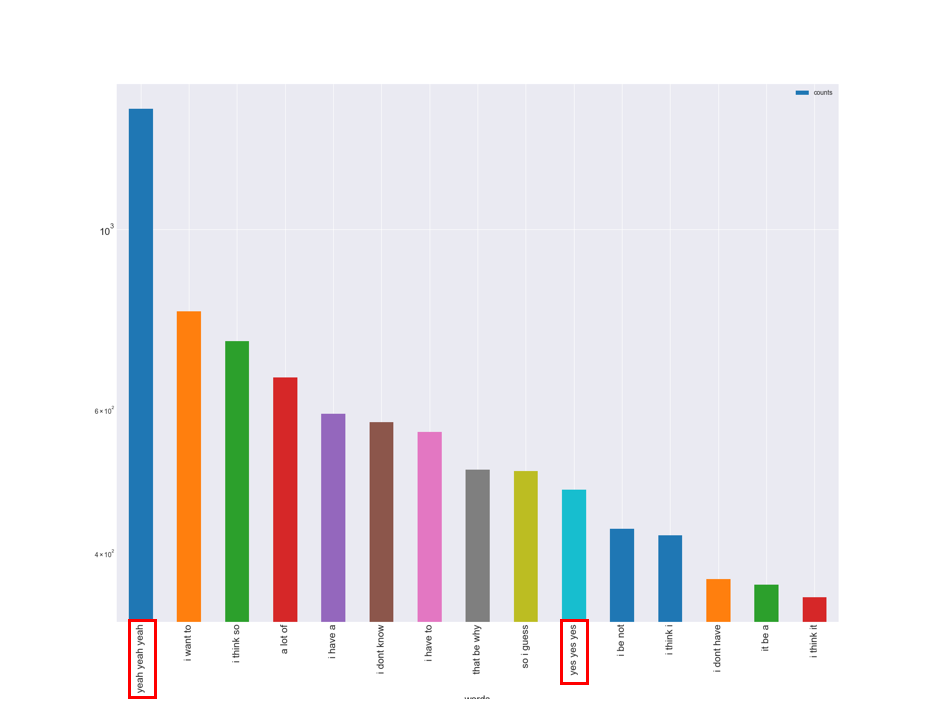
フレーズの頻度と大小関係を見れるようグラフで表現しています。また、y軸は尺度を対数で取っており、実際の出現頻度とは縮尺が異なるので解釈には気をつけてください。
結果をみてみると、N=2とN=3両方の1位に、先ほどの”yeah”が出現します。また”yes yes”も登場しており、先ほど出てきた”yeah”, “yes”, “ok”は相槌として使われていたのがわかります。
この結果を英語を母語とするスタッフに共有してみると、「相槌する際の言葉(backchannel)が多いのは兼ねてから不思議に思っていた」との反応を得られました。
実際に、ネイティブはyesやokは使うものの、会話ではexactlyやobviously、definitelyなど多様な語句を用いて相槌を打つとのことです。
また、類似の先行研究をみてみると相槌の分類6から始まり、ネイティブとノンネイティブの日本語や英語の会話に置ける聴き方の違い78や、日本語と英語の会話をネイティブとノンネイティブで比較した研究9も存在しています。より繊細に解析するとより詳細な日本人英語像が見えてくるかもしれません。CEFR10を踏まえて考えるなら、不自然さが解消されることで表現力や流暢さが高まることを期待できるでしょう。
まとめ
ネイティブと弊社のデータを用いて、私たちの日本人の英語の発話について考察しました。結果として、Iを中心とした言い回しの多さやsoとasの関係、そしてなんといっても相槌の多さが見えてきました。
今回の調査はあくまで表面的なものであり、文化や言語的特徴など、様々な背景から生まれる発話傾向の違いがどの程度、聞き手の印象に対して影響するかは議論の余地があります。
しかしながら、このように日常会話やビジネス英会話で、お互いが気持ちよく会話するためには私たちの発話傾向を知り、異なる言語での発話傾向の違いを知ることで、より円滑で活発なコミュニケーションがとれるようになっていくでしょう。
例えば今回の例で言えば相槌を”yeah”, “ok”, “yes”から”exactly”,”obviously”,”definitely”に変えるだけで、少し変化が出せるようになるでしょう。
今後もこのような考察を繰り返し、フィードバックを繰り返しながら、「日本人1,000万人を英語が話せるようにする。」というミッション達成に向けて歩みを進めたいと思っています。
参考
高村大也,『言語処理のための機械学習入門』奥村学監修, コロナ社
篠田浩一,『音声認識』(機械学習プロフェッショナルシリーズ), 講談社
1https://www.mhlw.go.jp/file/04-Houdouhappyou-11655000-Shokugyouanteikyokuhakenyukiroudoutaisakubu-Gaikokujinkoyoutaisakuka/1496p75g.pdf
2https://webrtc.org/
3https://github.com/amueller/word_cloud
4https://www.talkenglish.com/vocabulary/top-2000-vocabulary.aspx
5https://ja.wikipedia.org/wiki/%E5%85%A8%E6%96%87%E6%A4%9C%E7%B4%A2#N-Gram
6S. Maynard (1986), “On back-channel behaviour in Japanese and English conversation.” Linguistics 24.
7C. Hanazawa (2012), “LISTENING BEHAVIORS IN JAPANESE: AIZUCHI AND HEAD NOD USE BY NATIVE SPEAKERS AND LANGUAGE LEARNERS”, https://ir.uiowa.edu/cgi/viewcontent.cgi?article=3464&context=etd
8P. Cutrone (2010), “The Backchannel Norms of Native English Speakers; A Target for Japanese L2 English Learners”, LANGUAGE STUDIES WORKING PAPERS, Vol.2, 28-37, https://www.reading.ac.uk/web/files/english-language-and-literature/ell_language_Cutrone_vol_2.pdf
9S. Uematsu (2000), “The Use of Back Channels Between Native and Non-native Speakers in English and Japanese”, https://web.uri.edu/iaics/files/07-Shigeo-Uematsu.pdf
10Qualitative aspects of spoken language use – Table 3 (CEFR 3.3): Common Reference levels. https://www.coe.int/en/web/common-european-framework-reference-languages/table-3-cefr-3.3-common-reference-levels-qualitative-aspects-of-spoken-language-use
